
For the reasons we explored in our previous article, you have likely decided to move from manually crafted engineering drawings, like CAD maps, Visio schematics, and Excel splice tables, to a modern network information system.
As you begin planning this journey, you quickly realize you are facing an optimization problem. You are trying to balance the classic triple constraint: time, money, and data quality.

Naturally, you want to minimize the time and money required to transform legacy files into a structured system. However, if you push too hard on these constraints, you may sacrifice the third: data quality.
This creates a dangerous long-term risk. While you might replace your network information system every 10 to 15 years, the network infrastructure data itself is a foundational asset that must support your company for the long term, perhaps 50 years. Sacrificing the integrity of a 50-year asset to meet a short-term budget constraint is often a strategic mistake.
With these constraints in mind, what are the most critical aspects of a data transformation journey you should consider?
Note: When we discuss a data transformation project, we refer to the conversion of large volumes of file-based documentation into a modern information system, not merely migrating a few dozen engineering drawings.
What comes first: data or system?
Some operators decide to purchase and deploy a network information system first, and only when that variable is resolved do they initiate the data transformation project. Others do the exact opposite: they start with the data transformation even if they have not yet selected the target system.
Both approaches are possible, and both can be successful. In our experience, the critical insight is that successfully implementing a data transformation project requires entirely different skill sets than introducing a new network information system. This distinction will become more clear in our next article when we look back from the perspective of a completed project.
The approach: human versus machine
The next and even more strategic decision is the execution methodology. To solve the time, cost, and quality optimization problem, you must decide how much work to assign to a machine and how much to assign to a human. Let us explore the options.
Option 1: Fully manual data capture from scratch
Some operators decide to manually capture their physical network inventory anew in their recently deployed system. This means a capture team logs into the new network information system and starts drawing the network and entering data while visually referencing legacy file-based documentation on a second screen.
Usually, network information systems are not designed for massive data capture and are thus not optimized for it. If two or three additional, unnecessary clicks for each operation must be repeated thousands of times, a significant time overhead quickly accumulates, impacting your costs and timelines. In the past, probably due to this reason, this approach often involved outsourcing the work to regions with lower labor costs.
Crucially, with this approach it is nearly impossible to automatically check if the newly captured data in your information system corresponds to what is in your file-based documentation. Since the capture is manual, there is no digital link established between your existing files and the newly captured data; only visual inspection is possible.
In a capture team of twenty, or in some cases even hundreds of members, if some are more open to free interpretation of the data capture rules or simply fail to follow them, you may get inconsistent results at the end. This may directly contradict your goal of producing high-quality data that must support your business for the next few decades.
Option 2: The "full automation" black box approach
The extreme alternative to the fully manual approach is to fully automate data processing. This approach significantly saves time. Additionally, it ensures that all input documentation is subject to processing by the same consistent rules, unlike the fully manual approach where interpretation may vary between individuals. To achieve this, you might attempt to use general-purpose ETL software.
However, generic tools usually do not understand complex telecom logic. Telecom data is characterized by elements that are deeply nested and deeply connected. It is important to remember that most of the data in a physical network inventory database are not the network elements themselves, but the relations among them.
Generic tools often struggle with concepts like the containment of elements, such as trenches, ducts, and cables, or connectivity between elements at the same level, such as port-to-fiber connections. If the tool cannot handle these deep hierarchies and interdependencies, the results may be suboptimal.
Alternatively, you might replace generic ETL software with a fully customized batch-mode application, often offered by specialized service providers, that processes your documentation in a single run. While this often yields better structured data than a generic tool, it typically produces a long list of unresolved situations or exceptions found in the original documentation.
The temptation is to import the results while ignoring these exceptions, assuming you will fix them later inside the network information system. This is usually a mistake. Most network information systems are not designed as mass data cleansing tools. They are meant to support day-to-day operations, not large-scale data corrections or the resolution of complex cross-correlation issues. Your teams will probably not have the time or energy to do that alongside their daily work, creating a huge operational burden that may haunt you long after the project is closed.
Option 3: Balanced approach with high automation combined with human-in-the-loop
The third approach combines the advantages of the two extreme approaches.
The core of the transformation is a graphical user interface application with integrated, highly customized algorithms, whether rule-based or AI-based such as convolutional neural networks, for automated processing of your existing network documentation, including CAD, PDF, Visio, and Excel. Importantly, this approach combines fast machine processing with point-wise human intervention to provide immediate feedback, achieving the best quality while minimizing time and costs.
How does it work?
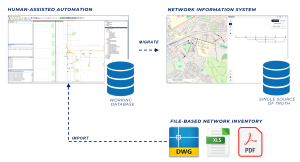
Data transformation journey
Generally, the algorithms process the network documentation in several steps, often achieving a 90-95% automation rate in each step. The results of each data processing step are immediately visualized, and a human expert, a capture team member, interactively handles the remaining 5-10% of data situations. These typically involve providing instructions to the algorithms on how to handle exceptions or errors in the original documentation that cannot be solved by standard rules.
Once the human provides input, the algorithm for that step is run again, this time resolving all data issues. This iterative process continues step-by-step until the data is processed 100%.
While the technical details, such as manual intervention objects, automated tickets, and cross-referencing multiple sources, are beyond the scope of this article, the goal is clear: to enable the inspection and confirmation of data quality before migration into your network information system takes place. This ensures you have clean data before it enters the network information system, while the high automation rate minimizes costs and time.
A note on technical complexity
As you may have noticed, we have not discussed the intricacies of file-based physical network inventory documentation in this article. Nor have we touched upon the specific operations applied to that documentation to generate structured data. There are dozens of data processing tasks handling geometry, topology, and attributes which are required for success. We may discuss these complexities in a future article intended for a technical audience.
In our next post, we will look at some lessons operators wish they had known before they started with this data transformation journey.